fine-tuning a Phi3.5 SLM on Windows via WSL to make a chatbot that sounds like me
hahahahaha
ok the plan is: 1. take my blog posts and turn them into paired data. 2. fine-tune a SLM. 3. chat with myself
starting with this tutorial: https://robkerr.ai/fine-tuning-llms-using-a-local-gpu-on-windows/
opened powershell in administrator. typed wsl --install. it didn’t give me any errors. typed wsl. got…
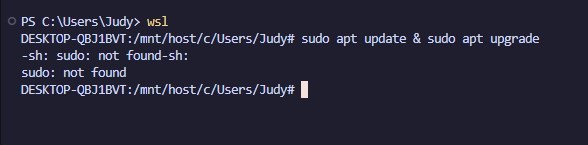
ok, i think i have a different set of instructions for installing WSL because i am on Windows 10, not Windows 11. hahaha. now using: https://learn.microsoft.com/en-us/windows/wsl/install-manual
that worked! somehow installing ubuntu from… the microsoft store?
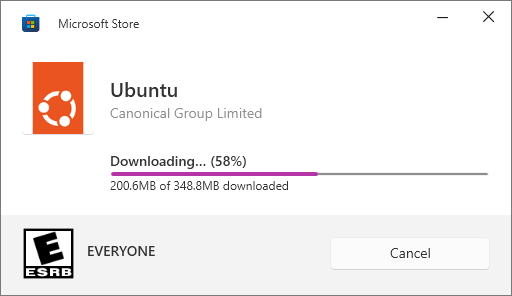
then
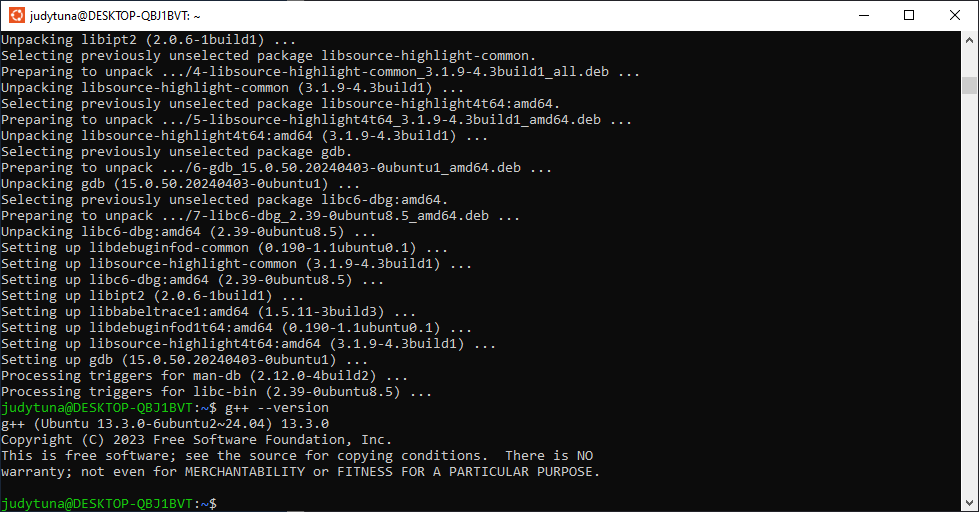
installing miniconda
xformers caused me to have an unresolvable environment, so i removed it and ran
conda install pytorch-cuda=12.1 pytorch cudatoolkit -c pytorch -c nvidia
and i think that’s the end of how far i’ll follow this tutorial, cuz i don’t think i’m using unsloth. edit: i found out the reason why! unsloth does not have mac compatibility! should i start this whole project over using unsloth?!?!?!? i’m gonna do that if run 7 fails to change the model again
i am using ollama!
curl https://ollama.ai/install.sh | sh
pip install -r requirements.txt
oh god WSL was like “you can’t flyer me, i quit”
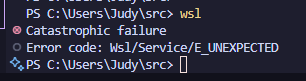
anyway then a day passed wherein i ran train_model.py 6 times and it did not change the conversation style at all.
- the 0th run hung at 0% complete because the VRAM was full. (edit: this version of markdown does not support the https://spec.commonmark.org/0.27/#example-228 lol)
- first attempt at creating training data out of my blog posts: make each post into paired data. the input is the post title, and the output is the post body. outputs are truncated to 500 characters to try to not make the VRAM full. but i also changed a bunch of the parameters, cuz i realized they were optimized for Ankeet’s machine.
- character limit on outputs is now 8000 characters.
- i had around 800 posts, which wasn’t enough pairs. augment data by cutting blog posts down into chunks at a random number of character, then asking “what next?” as the input, with the next chunk of post as the output. trained for a few hours; still no change.
- changed the way blog posts are chunked and turned into pairs. instead of the input being “what next?” over and over again, the input is now chunk A and output is chunk B. next pair input is chunk B and output is chunk C. this went for about four hours overnight. still no change.
- what about bigrams and trigrams? Run 5 was gonna take an estimated 1000 hours, which is like 41 days (all data: n-grams for n=1,2,3). i stopped it.
- ok, sample 20% of the n-grams. Run 6 was gonna take 240 hours, which is 10 days (medium data: 20% sampline of the n-grams). i stopped it.
- CURRENT! got rid of the n-grams altogether. this is using the same data as run 4, except the parameters are more aggressive. Run 7 is estimated to take 20ish hours LOL yay! (lite data: no n-grams rofl. 12,299 pairs of training data (the other 20% are validation pairs), filesize 8.4MB)
now we are at 2% progress on this 7th try haha:
